
https://arxiv.org/abs/2106.00445
Introduction
2022今時点でのNoisy Labelは二つの方向性がある。ノイズ変換行列と、正しそうなサンプルを選ぶというもの。前者は実データがインスタンス依存である、条件が複雑なのもあって性能が頭打ちしているように見えている。本論文は後者のSample Selectionについて論じる。
ではどのような基準でSample Selectionするかが問題。Memorization Effectにより、DNNはまずは本質的なパターンを覚えたうえで、ノイズに過学習していくので、本質的なパターンを覚えた時に小さい損失を持つサンプルがCleanなラベルを持ってると考えられそう=Small Loss Trick。これが現行の主流の考え方。
しかし、損失が小さいものをただ選ぶだけだと決定性になってよくないよね。一度間違った方向性を選ぶとこの傾向がずっと拡大してしまう。また、たとえCleanでも大きな損失を持つ一部のサンプルが学習されないという問題がある。
一例として、Imbalanced Dataの学習をするとき、損失が大きい理由として、同じカテゴリのサンプルを一杯学習してないからという原因もあるわけで。
これを解消するために、不確定性をSample Selectionに導入した手法を提案する。
Method
問題設定
- クラス分類であり、入力空間と出力空間であるとする。
- 学習器はであり、出力するのはそれぞれのクラスについての特徴。回目のイテレーションでの学習器パラメタをとする。
- 損失関数はとして、特徴を受け取って損失を計算する。この損失を最小化していくことが目標である。同様に回目のイテレーションでの損失をとする。
- 毎回の損失をすべて含んだ集合を考える。
- この論文では、がマルコフ過程に従うと仮定する。
Extended Time Intervals
有限の訓練時間を持つとき、ノイズが多いクラス事後推定における不安定性の問題にうまく対処できないらしい。推定の最初で間違ったのを選ぶとまずい問題なのかな?
1つの考えとして、と平均を取ることで、過去の損失を利用した情報を得る。より頻繁に各epochの平均を取る方が望ましい。
提案手法(Robust Mean Estimation and Conservative Search)
平均を取るという手法を拡張する。Soft Truncation, Hard Truncationの2つを提案する。truncation=切り捨て。どれを使うかはいくつかの仮定に基づく統計的検定によって決まるらしい。
Soft Truncationでは、外れ値に強く反応しないようにした写像による変換で解決させる。Hard Truncationでは、外れ値を排除したあとに平均を取る。
Soft Truncation
次のように平均っぽいものをとる。
指数関数のマクローリン展開を二乗の項までにして打ち切っている。これによって、極端な外れ値による影響を小さくすることができる。
Hard Truncation
の中でKNNアルゴリズムを使うことによって、個の外れ値検出ができる。具体的にがいくつかはアルゴリズムから自動的に検出される。他の検出アルゴリズムでも問題ないが、計算コストはKNNが一番低い。
検出した外れ値をから除外した集合をとする。そして、それの平均を取ることが、Hard Truncation。
Soft Truncation & Hard Truncationの集中不等式
Soft Truncationに対しては以下の集中不等式がある。

Hard Truncationに対しては以下の集中不等式がある。
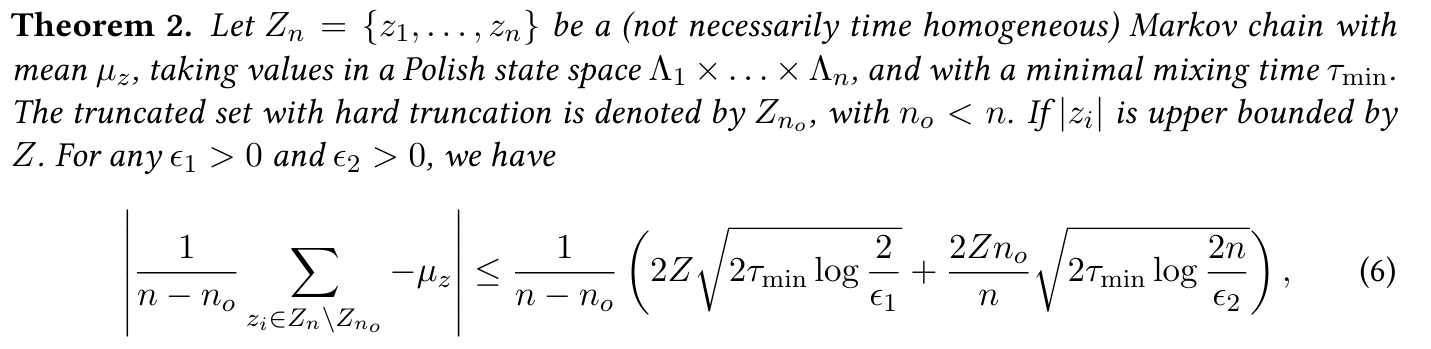
なんだかよくわからないが、訓練の損失上界をとしている。
保守的な探索と選択基準
上の集中不等式を用いた、保守的な探索をするらしい。気持ちとしては、集中不等式の上界をそのまま使うので、かなり確実なサンプル以外は選ばない、ということ。
今まで回のイテレーションで、あるサンプルが回選ばれたとする。ここで、として、Soft Trunctionを考えると、以上の確率で、まさにあの式が成り立つ。この時、損失の基準を
として、small loss trickを駆使すれば、ちょうど集中不等式に含まれない部分を使わない、という基準にすることができる。
同様に、Hard Trunctionでは、とすることによって、以下のよう閾値を設ける。
imbalanceな学習で、あまり訓練中で選択されなかった例はが成り立つ。その結果、分母の部分で上限が大きく増えることになる。なので、すべての訓練損失の平均を取るのではなく、固定長(XXepochごとに)ごとに平均をとる。こうすることで、全体の傾向をつかめる。
については、が少ないと値は多く引かれて、小さくなる。小さい方が良いらしいがなぜなんだ?
選択基準(7)および(8)については、二つの項から構成されており、一つの項にはマイナス記号が付いています。式(7)(または式(8))の第一項は小さい損失の例の不確実性を減らすためで、ここではトレーニング損失に堅牢な平均推定を使用します。第二項、すなわち統計的信頼区間は、ネットワークに選択された回数が少ない例(小さいntを持つ)を選ぶことを奨励します。これら二つの項はσ^2またはτminで制約されバランスを取っています。損失の基本的な分布に強い仮定を導入することを避けるため【8】、ノイズがある検証セットでσとτminを調整します。誤ってラベル付けされたデータについては、モデルはそれらに高い不確実性を持っています(つまり、小さいnt)そしてそれらを選びがちですが、誤ってラベル付けされたデータへの過剰適合は有害です。また、議論されているように、誤ってラベル付けされたデータとクリーンなデータを区別することは、場合によっては非常に困難です。したがって、保守的な方法で基本的なクリーンなデータを探すべきです。本論文では、σとτminを小さな値で初期化します。この方法は誤ってラベル付けされたデータの悪影響を減らし、同時に大きな損失を持つクリーンな例を選択することができ、これが一般化を助けます。より多くの評価は第3節で提示されます。
アルゴリズム
Co-Teachingを行う。

(4, 5ステップ)では、さきほど決めたの閾値に従って、損失が小さいものを選択している。でどれほどの割合を選ぶかを決めており、内実はの閾値で判断している。
最初はは大きく=大量のサンプルで学習するが、最終的には小さくなって一部のサンプルで学習するということになる。これはMemorization Effectによって、はじめは大量にやって簡単な特徴をつかんでもらい、細部の記憶をするときはCleanだと思われるラベルだけを使うというものである。